El objetivo de realizar un análisis de regresión y correlación es estudiar la relación existente entre dos variables aleatorias. Una de ellas se denomina variable independiente (o covariable), y es la que está sujeta a control del experimentador y se representa en el eje de abscisas como X. La otra se denomina variable dependiente y su valor depende del que tome la variable independiente, representándose en el eje de ordenadas como Y.
Aunque es usual que haya cierta confusión en relación a lo que estudia un análisis de regresión y un análisis de correlación, ambos ofrecen información complementaria. El análisis de regresión estudia la forma en que ambas variables aleatorias están relacionadas, mientras que el análisis de correlación investiga la fuerza de dicha relación.
Antes de realizar los primeros pasos en el análisis de regresión, es recomendable identificar cuál de nuestras variables se comporta como la variable X y cuál se comporta como la variable Y. Cuando se realizan correlaciones, la elección de qué variable es una u otra no es importante, siempre y cuando seamos consistentes en la elección para todos los datos. Pero cuando se ajustan los datos a un módelo para realizar predicciones, la elección de X e Y hay que tenerla en consideración.
- En general, la variable X es la variable predictora o explicativa, porque si X cambia, la pendiente de la regresión nos cuenta (o explica) cuánto se espera que cambie Y.
- Por su parte, la variable Y se conoce como variable respuesta porque si X cambia, la respuesta (según la ecuación de la línea) es un cambio en la Y. Por lo tanto, Y puede ser predecida por X si existe una relación fuerte entre las variables.
Quiero leer...
5.1 Regresión Lineal Simple
La regresión lineal simple viene del planteamiento en la que existen dos variables aleatorias (X e Y) que están relacionadas linealmente bajo la ecuación general de una recta. Los 2 parámetros beta se denominan coeficientes de regresión.
Los datos provenientes de los diámetros mesiodistal (MD) y bucolingual (BL) de los dientes de Neandertales (Lumley and Giacobini 2013) son un buen ejemplo para poder mostrar la regresión lineal simple. Estos datos los tenemos ya cargados en R Commander con el nombre de Molares. Estos datos pueden descargarse de la web del libro con el nombre Lumley and Giacobini 2013. Molares inferiores Neandertales.txt).
5.1.1 Tipos de relación en un diagrama de dispersión
Los diagramas de dispersión (conocidos en inglés como scatterplots) son muy útiles para ver cómo se relacionan dos variables cuantitativas, como son en este caso MD y BL. Por lo tanto, es muy útil que antes de realizar un análisis de regresión se observe a priori si es útil aplicar una regresión lineal o no a nuestros datos.
A través de la observación de la tendencia de los datos en un diagrama de dispersión se puede identificar los tipos de relación existetes entre la variable independiente y la dependiente:
- Si al aumentar X aumenta Y, estamos ante una relación positiva.
- Si al aumentar X disminuye Y, estamos ante una relación negativa.
- Si no existe ningún tipo de patrón identificable entre ambas variables, entonces no hay relación.
5.1.2 Diagrama de dispersión
Para realizar un Diagrama de dispersión en R Commander se sigue la siguiente ruta (Figura 59): Graphs - Scatterplot.
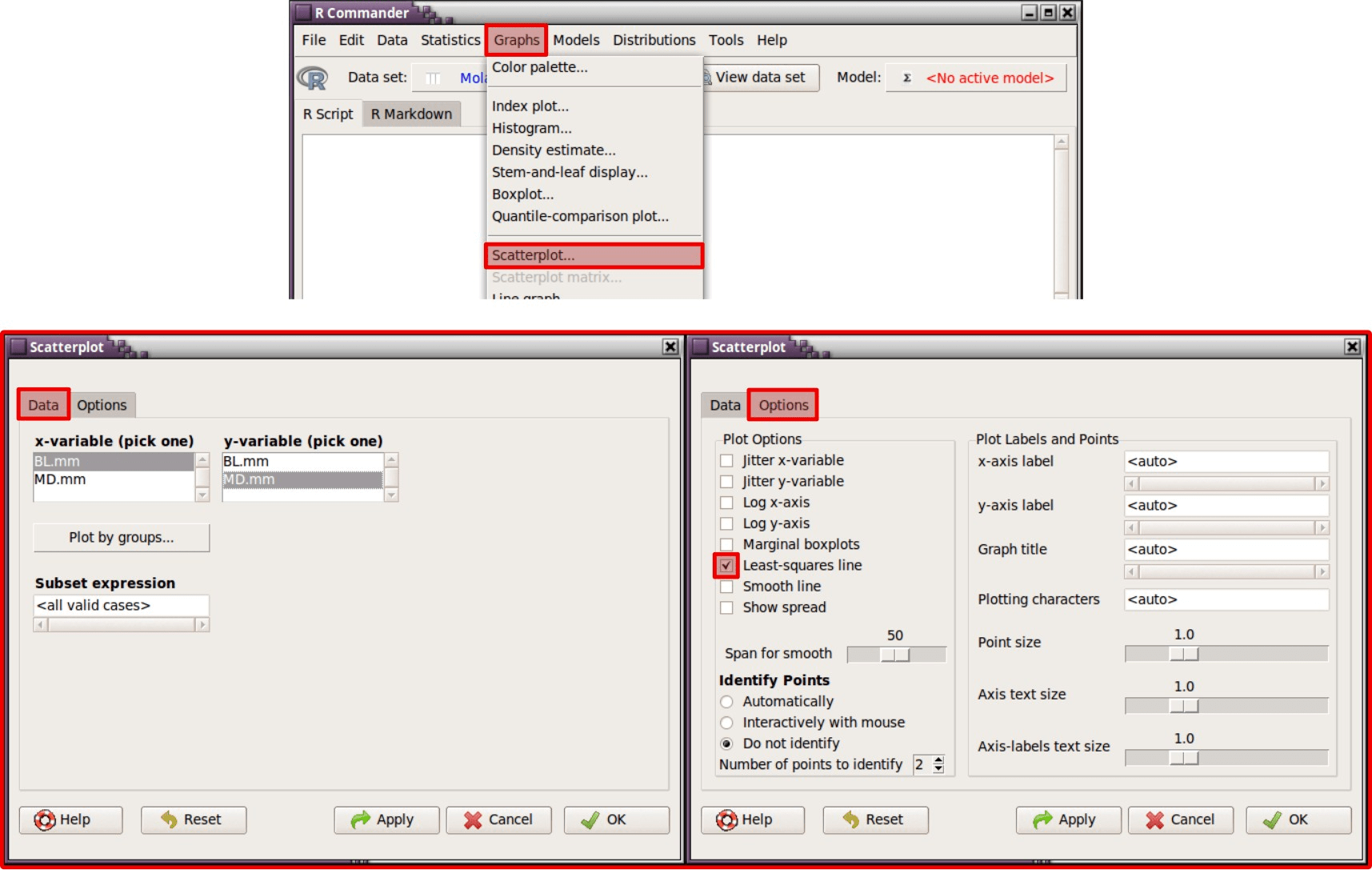
Figura 59: Diagrama de dispersión para las dimensiones de los molares de Neandertales, incluyendo la línea de tendencia de mínimos cuadrados (Least-squares line).
Al realizar un diagrama de dispersión, hay que seleccionar cuál es la variable que se va a encontrar en el eje de abscisas (X) y qué variable en el eje de ordenadas (Y), dentro de la pestaña Data.
En la pestaña Options, aparecen ciertas características que son interesantes. Se pueden convertir los ejes en logaritmos, añadir en los márgenes los diagramas de caja y bigotes, etc. Se marca la opción de línea de mínimos cuadrados (Least-squares line) y se ve el resultado del diagrama de dispersión con su línea de tendencia central en la Figura 60.
scatterplot(MD.mm~BL.mm, reg.line=lm, smooth=FALSE, spread=FALSE, boxplots=FALSE, span=0.5, ellipse=FALSE, levels=c(.5, .9), data=Molares)
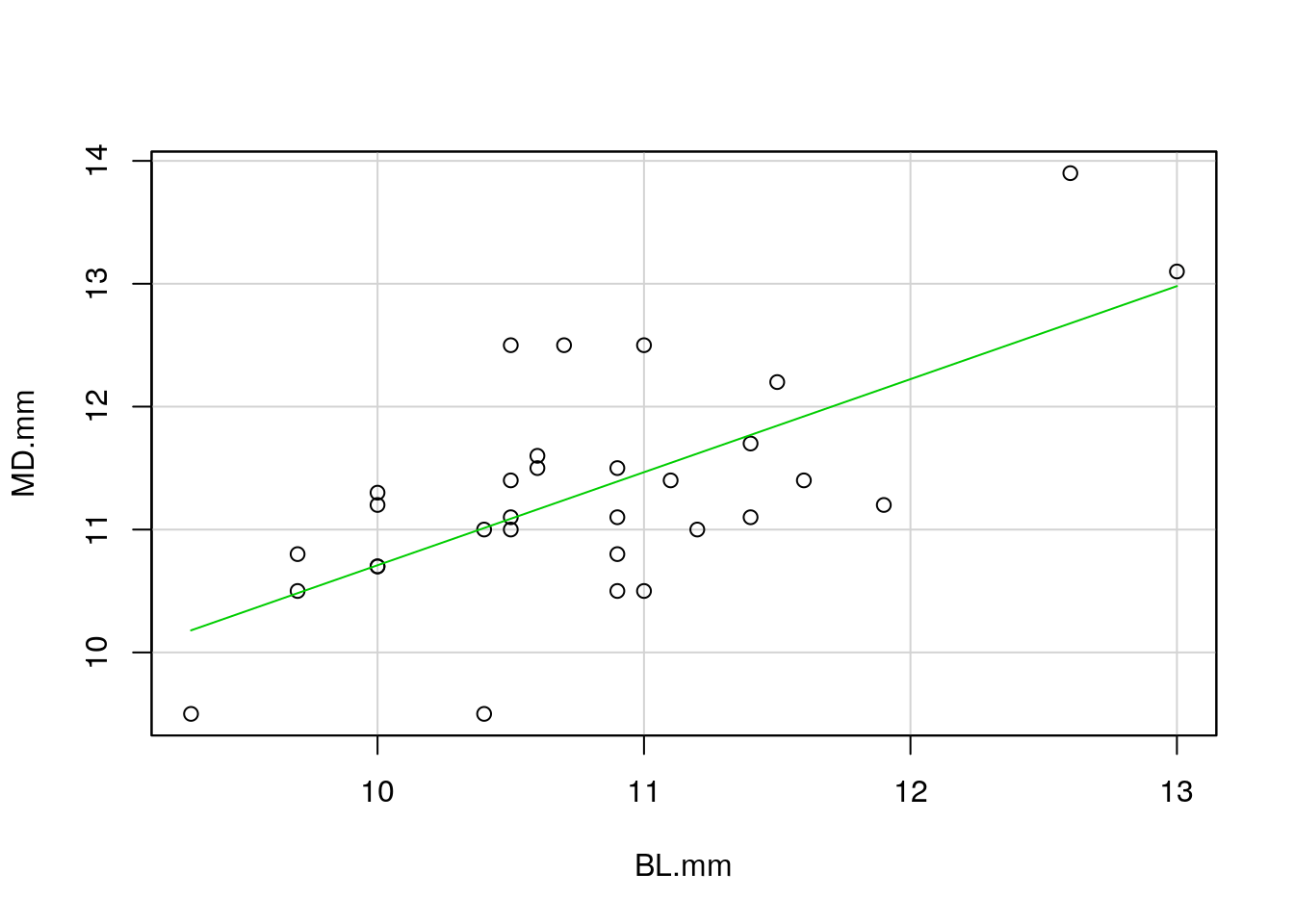
Figura 60: Diagrama de dispersión y línea de tendencia central de los datos de las dimensiones de los molares de homininos fósiles.
5.1.3 Línea de mínimos cuadrados y residuos
La línea de mínimos cuadrados marcada en la Figura 60 en color verde, también llamada línea de tendencia central se forma en base a los residuos. Los residuos son la distancia en el eje Y entre la observación real y la línea de tendencia (Figura 61). Por lo tanto, habrá tantos residuos como observaciones.
La línea de mínimos cuadrados pasa por el sitio donde la suma de los residuos de todas las observaciones al cuadrado es mínima. Y se hace al cuadrado precisamente para evitar la presencia de los números negativos.
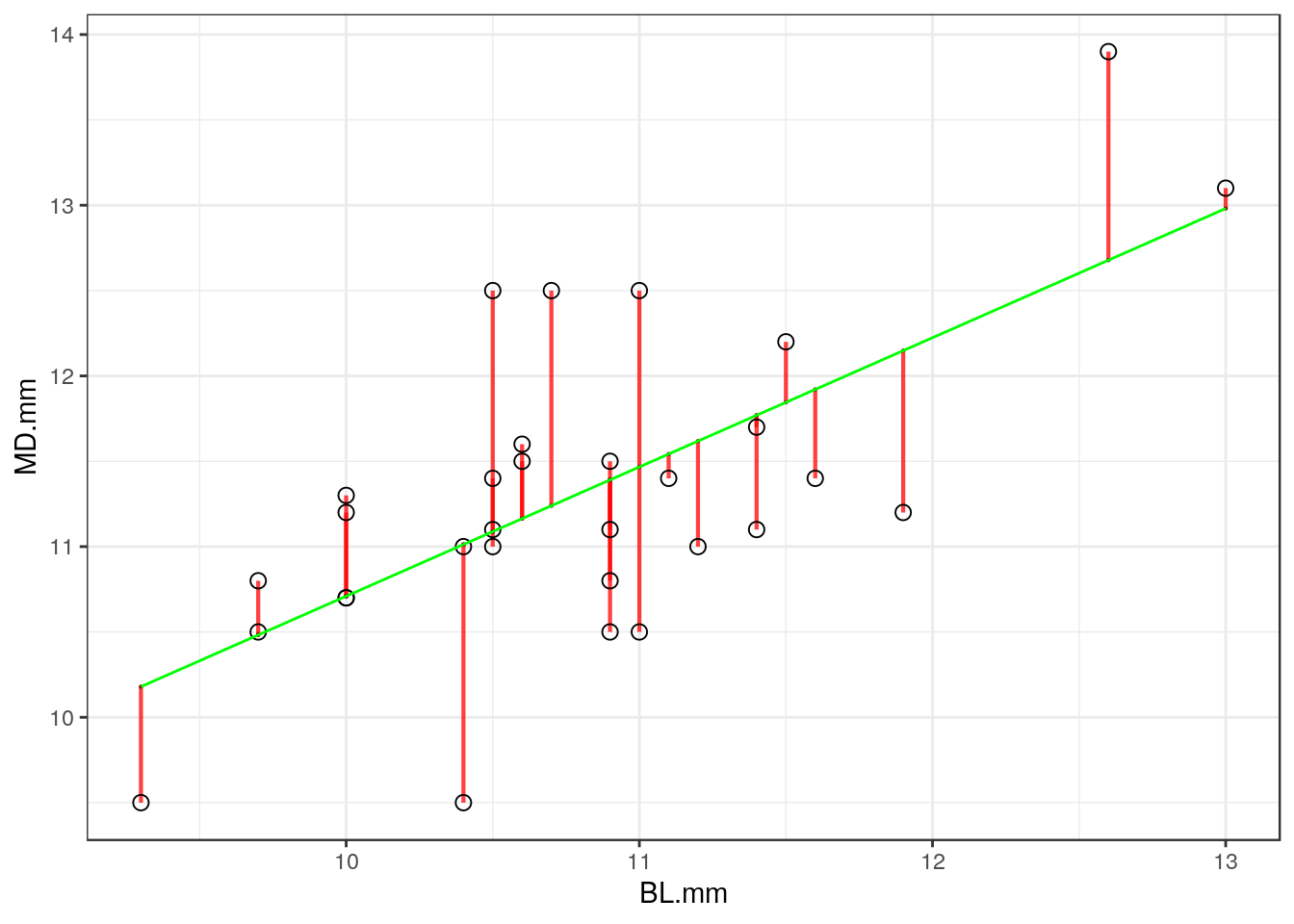
Figura 61: Diagrama de dispersión con los residuos de cada una de sus observaciones marcados en segmentos rojos.
Observando con detenimiento la Figura 61 se pueden ver las distancias de los residuos. Y los residuos en una regresión lineal simple tienen que cumplir una propiedad: que estén distribuidos siguiendo una distribución normal.
De hecho, si se juntan los 31 residuos (correspondientes a los 31 molares), se puede generar una nueva variable que puede ser analizada. Esta variable puede añadirse al conjunto de datos (Molares) siguiendo la siguiente ruta (Figura 62): Models - Add observation statistics to data....
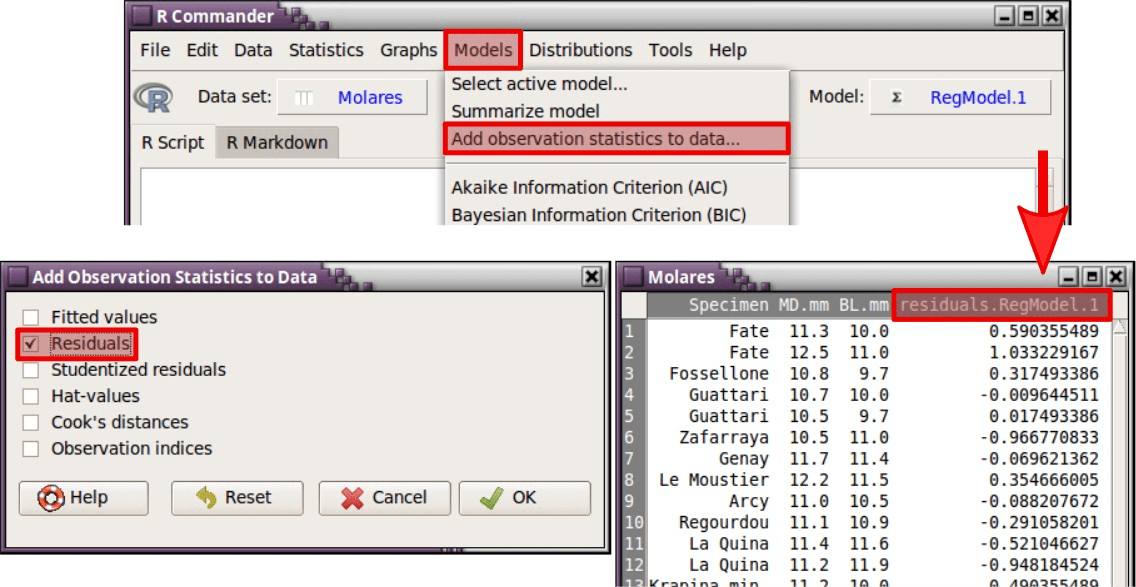
Figura 62: Modo de añadir los residuos al conjunto de datos activo en R Commander.
En la ventana que se abre se selecciona la opción Residuals y se presiona sobre OK. Se añade una nueva columna en el conjunto de datos con el nombre de residuals.RegModel.1. Es sobre esta variable donde se contrasta la normalidad, observando que efectivamente, los residuos se comportan siguiendo esta distribución (p-valor > 0.05).
shapiro.test(Molares$residuals.RegModel.1)
## ## Shapiro-Wilk normality test ## ## data: Molares$residuals.RegModel.1 ## W = 0,97331, p-value = 0,614
5.2 Correlación de una regresión lineal simple
La correlación sirve para medir la fuerza de la relación entre las dos variables. Una correlación implica ejecutar un contraste de hipótesis, a saber:
- H0: X e Y no están relacionadas linealmente (pendiente = 0)
- H1: X e Y están relacionadas linealmente (pendiente ≠
- 0)
Las correlaciones, independientemente de qué modelo provengan, presentan dos características fundamentales:
- Son adimensionales. Esto significa que su valor ese independiente de la unidad de medida que estemos tomando.
- El coeficiente de correlación no varía intercambiando las variables entre X e Y.
Hay una opción directa en R Commander para ejecutar una regresión lineal simple. Aunque es necesario mencionar que en la ventana que se despliega con las opciones siguiendo este método, las variables presentan diferentes nombres:
- A la variable Y la llaman Response variable (variable respuesta o dependiente).
- A la variable X se la identifica con el nombre de Explanatory variable (variable explicativa o independiente).
Simplemente hay que seguir la siguiente ruta (Figura 63), donde se indica que la variable Y sea MD.mm y la variable X sea BL.mm: Statistics - Fit models - Linear regression....
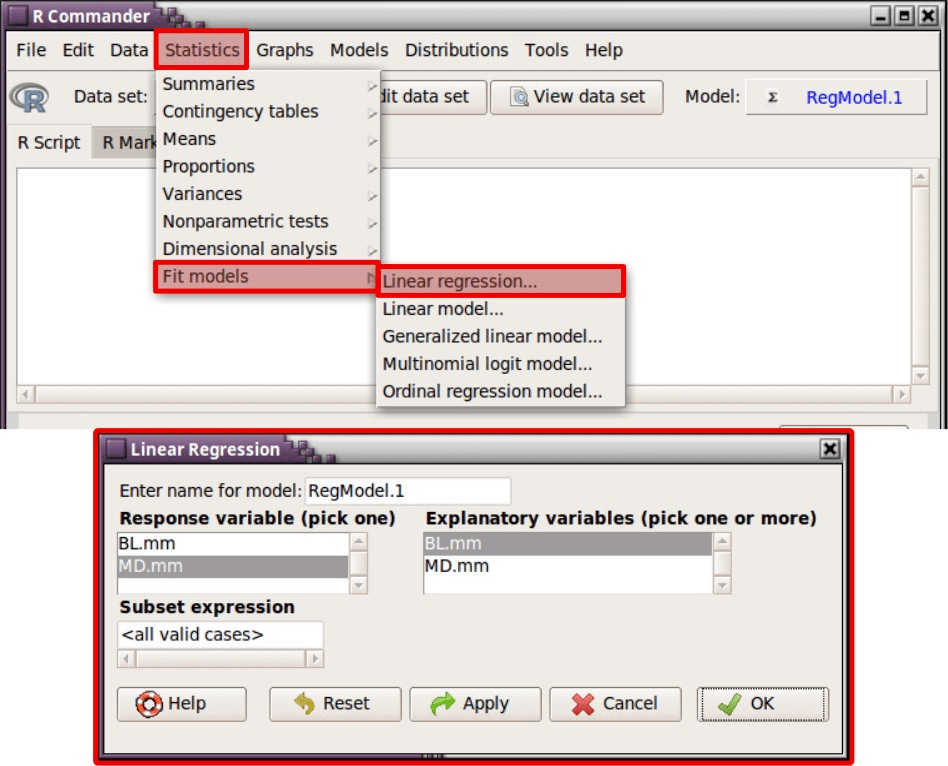
Figura 63: Modo de añadir los residuos al conjunto de datos activo en R Commander.
Es importante tener en cuenta el nombre del modelo o regresión que se genere. Si es el primer modelo creado, R Commander lo renombra automáticamente poniendo el nombre de RegModel.1. Al dar al OK, aparece en la esquina superior derecha de R Commander como Model: RegModel.1 (Figura 63). Los resultados se muestran a continuación:
RegModel.1 <- lm(MD.mm~BL.mm, data=Molares) summary(RegModel.1)
## ## Call: ## lm(formula = MD.mm ~ BL.mm, data = Molares) ## ## Residuals: ## Min 1Q Median 3Q Max ## -1,51250 -0,55605 -0,00964 0,34537 1,41179 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 3,1384 1,7230 1,821 0,0789 . ## BL.mm 0,7571 0,1592 4,757 0,0000498 *** ## --- ## Signif. codes: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 ## ## Residual standard error: 0,703 on 29 degrees of freedom ## Multiple R-squared: 0,4383, Adjusted R-squared: 0,419 ## F-statistic: 22,63 on 1 and 29 DF, p-value: 0,00004979
5.2.1 Interpretar el resultado
Entre todo el conjunto de resultados que nos devuelve R Commander, lo más destacado son la ecuación, los valores de sus coeficientes, los p-valores de los coeficientes, el p-valor de la regresión, los coeficientes de correlación y R cuadrados.
La ecuación se observa en la sección de Coefficients, donde se encuentra la columna Estimates, que se corresponde con los valores de los coeficientes. Por lo tanto, la ecuación del modelo de regresión lineal recién generado sería la siguiente, donde Y es MD.mm y X es BL.mm.
MD.mm=0.7571×BL.mm+3.1384
A continuación hay que fijarse en los p-valores. Los resultados OFRECEN 3 p-valores, dos asociados a la sección de Coefficients, donde uno va en relación con el intercepto y el otro con la pendiente (β
) y uno general al final de los resultados y después de los R cuadrados.
Puesto que el contraste de hipótesis indica si hay relación o no entre las variables, y puesto que para determinar esto el contraste utiliza el valor de la pendiente y su igualdad o no a 0, es fácil comprender que el resultado del p-valor de la pendiente sea el mismo que el resultado general, como así sucede.
El p-valor asociado al intercepto responde también a un contraste de hipótesis, en el que la hipótesis nula es que la pendiente sea 0, mientras que la hipótesis alternativa sería que la pendiente ≠
0.
Con un nivel de significación de 0.05, se puede decir que existen evidencias estadísticamente significativas para justificar una relación lineal entre las dos variables del estudio (MD.mm y BL.mm), ya que el p-valor de la regresión y pendiente es menor a 0.05 (4.979e-05). Este valor hace que se rechace la hipótesis nula de no dependencia lineal, y se acepte la hipótesis alternativa que indica que realmente existe una relación lineal entre ambas variables. El intercepto, por su parte muestra que su p-valor es mayor a 0.05, aceptando la hipótesis nula de que su valor es igual 0.
Pero… ¿cómo podemos entonces interpretar estos valores en relación con las variables?
La pendiente (β
) indica cómo de inclinada está la recta. Puede tomar los siguientes valores:
- β
> 0. La pediente es positiva. β = 1. Pendiente de 45º positivos. β < 0. La pendiente es negativa. β =-1. Pendiente de 45º negativos. β
= 0. No hay pendiente (es horizontal).
El valor de pendiente en el ejemplo es 0.7571, lo que indica que la pendiente es positiva, aunque algo menor de 45º positivos. Esto significa que cuando BL.mm aumenta, MD.mm también lo hace pero a un ritmo menor. El crecimiento de ambas no es proporcional.
El intercepto representa el valor de MD.mm cuando BL.mm es 0. Sin embargo, no tiene sentido que al ser BL.mm = 0, MD.mm tenga 3.14 mm. Entonces… ¿por qué aparece ese valor? ¿quiere decir que el modelo es erróneo? Aquí entra en juego el porcentaje de variación que explica el valor de Y a través de la variable X. Lo que se conoce como coeficiente de correlación y determinación.
La fuerza de la relación entre estas dos variables numéricas depende de cuán cerca estén las observaciones de un cierto patrón, en este caso lineal. Es decir, dependerá de la proximidad que tengan las observaciones respecto a la línea de mínimos cuadrados. Los estadísticos usan el coeficiente de correlación para medir la fuerza y la dirección de la relación lineal entre las dos variables. El coeficiente de correlación se representa por la letra erre (r) y siempre está comprendido entre +1 y -1. Sus valores se pueden interpretar como se mencionan a continuación:
- Exactamente -1. Indica una relación lineal perfecta negativa.
- Próximo a -1. Indica una relación lineal negativa muy fuerte.
- Próximo a 0. Significa que no hay una relación lineal.
- Próximo a +1. Indica una relación lineal positiva muy fuerte.
- Exactamente +1. Indica una relación lineal perfecta positiva.
Unos ejemplos de coeficiente de correlación en diagramas de dispersión pueden verse en la Figura 64.
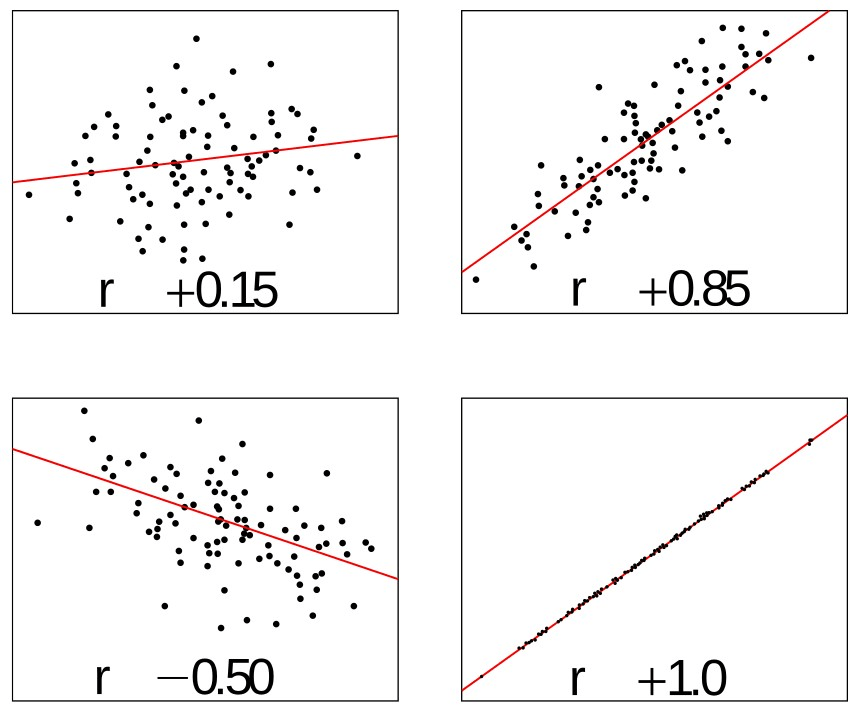
Figura 64: Modo de añadir los residuos al conjunto de datos activo en R Commander.
El R cuadrado es el porcentaje de variación que presenta la variable Y en relación con una o más variables X. Se conoce también como coeficiente de determinación y su valor se encuentra entre 0 y 1.
El R cuadrado ajustado es el porcentaje de variación que presenta la variable Y en relación con una o más variables X, ajustado para el número de predictores en el modelo. Este ajuste es necesario porque el R cuadrado de cualquier modelo siempre aumentará cuando se agregue una nueva variable, y con este ajuste se evita ese problema. Se conoce también como coeficiente de determinación corregido y su valor se encuentra entre 0 y 1.
En el ejemplo, el R cuadrado ajustado es 0.419. Este valor significa que el modelo de regresión explica el 41.9%. Es decir, hay un 58.1% que no explica y esto se debe a la dispersión de los datos. El hecho de que sólo explique el 41.9% de la variación hace que haya mucha incertidumbre y desconocimiento sobre qué otras variables son las responsables del 58.1% de variación restante no explicada. Este es uno de los motivos por los cuáles MD.mm tenga el valor de 3.14 mm cuando BL.mm es igual a 0.
De lo explicado se desprende que cuanto mayor sea el valor del coeficiente de determinación corregido (lo más próximo al valor 1), mejor será la correlación a los datos.
5.3 Correlación de una regresión polinomial
Los fundamentos teóricos para comprender una regresión polinomial son los mismos que los descritos en la regresión lineal simple. La única diferencia aquí son las ecuaciones. Al ser una regresión polinomial, la ecuación deberá ser polinómica de dos grados (cuadrática), de tres grados (cúbica), de cuatro grados, etc.
El ejemplo para ilustrar una regresión polinomial cuadrática proviene de un artículo publicado en American Journal of Physical Anthropology sobre un método de reconstrucción de dientes desgastados (Modesto-Mata et al. 2017). A partir de una imagen estandarizada de microtomografía computarizada, se ha obtenido el perfil del esmalte de los molares de humanos modernos. Cada uno de estos perfiles está definido por 51 puntos, donde sus coordenadas están relativizadas de 0 a 100 en ambos ejes (Figura 65).
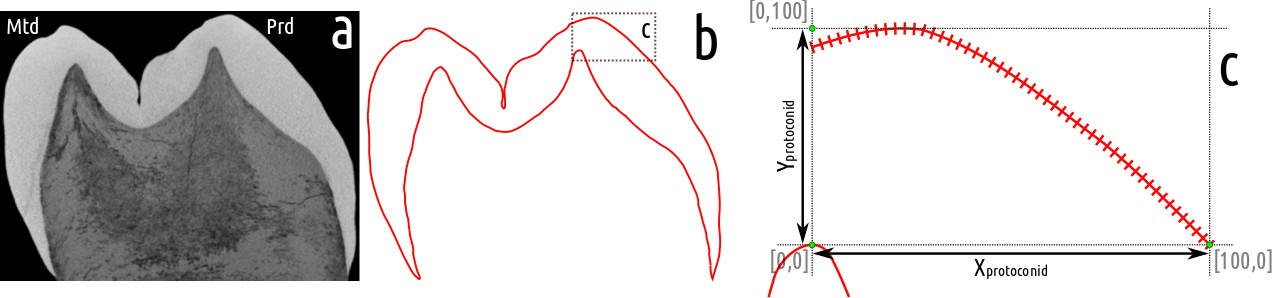
Figura 65: Plano microtomográfico de un molar (a) con el perfil del esmalte (b) y la zona de estudio de la cúspide derecha con los 51 puntos (c).
En este ejemplo se van a usar los datos de 3 molares, por lo que existirán en total 153 coordenadas o puntos. Los datos pueden descargarse desde la web del libro con el nombre Curvatura esmalte molares.txt. Al importarlos en R Commander, se ha llamado al conjunto de datos como curvatura.
Primero se realiza un diagrama de dispersión para ver cómo se distribuyen los datos (Figura 66), pero sin marcar la opción de Least-square line, ya que no es una línea lo que estamos buscando.
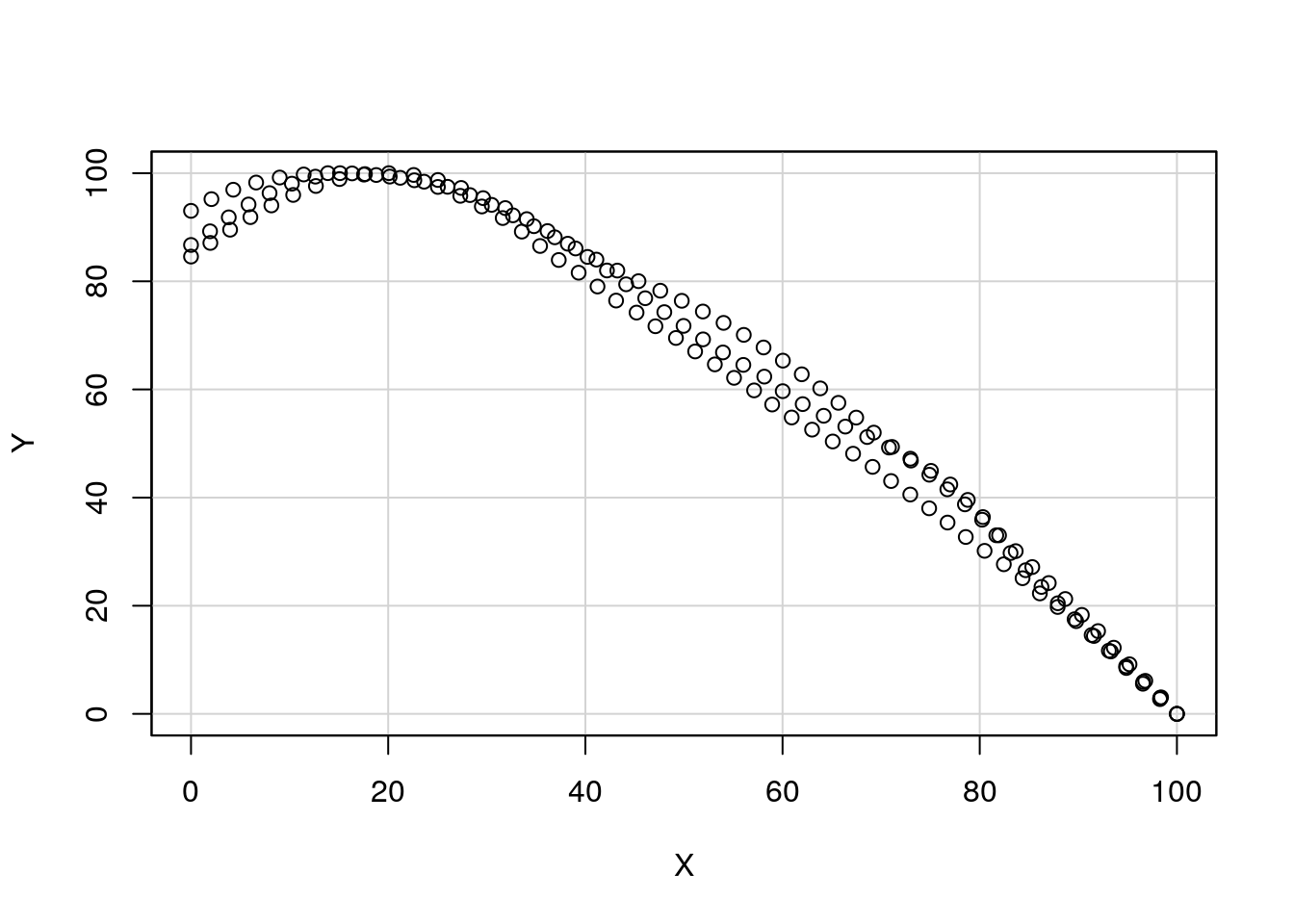
Figura 66: Diagrama de dispersión de los 153 puntos o coordenadas relativas de 3 molares de humanos modernos.
Como se observa claramente, una línea recta no se ajustaría bien a las observaciones. Llegados a este punto, hay que introducir manualmente la fórmula nosotros. Para ello, seguimos la ruta Statistics - Fit models - Linear model.... y se escribe la fórmula tal y como se ve en la Figura 67.
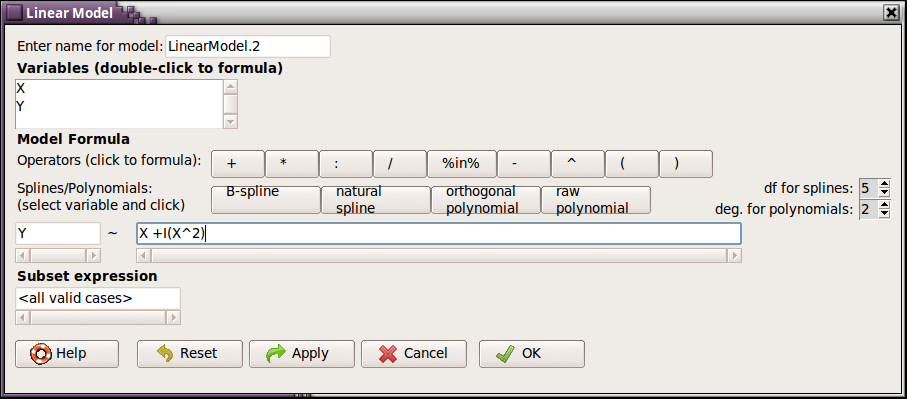
Figura 67: Escritura de la fórmula polinómica cuadrática (segundo grado) en R Commander.
Esta fórmula se escribe siguiendo la siguiente estructura: Nombre_Variable_Y ~ Nombre_Variable_X + I (Nombre_Variable_X^2). Para los nombres de las variables del ejemplo, se muestran en la Tabla 18 cuáles son las fórmulas que se han de escribir en el área específica de R Commander.
| Regresión polinomial | Fórmula |
|---|---|
| Segundo grado | Y = X + I(X^2) |
| Tercer grado | Y = X + I(X^2) + I(X^3) |
| Cuarto grado | Y = X + I(X^2) + I(X^3) + I(X^4) |
Tabla 18: Fórmulas para escribir las ecuaciones polinómicas en R Commander con los datos del ejemplo.
El resultado de dicho modelo de regresión se observa a continuación:
LinearModel.2 <- lm(Y ~ X + I(X^2), data=curvatura) summary(LinearModel.2)
## ## Call: ## lm(formula = Y ~ X + I(X^2), data = curvatura) ## ## Residuals: ## Min 1Q Median 3Q Max ## -12,248 -2,820 1,266 2,332 6,308 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 96,8219608 0,9248629 104,688 <2e-16 *** ## X 0,0985415 0,0415485 2,372 0,019 * ## I(X^2) -0,0109347 0,0003954 -27,657 <2e-16 *** ## --- ## Signif. codes: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 ## ## Residual standard error: 3,839 on 150 degrees of freedom ## Multiple R-squared: 0,9854, Adjusted R-squared: 0,9852 ## F-statistic: 5075 on 2 and 150 DF, p-value: < 2,2e-16
Todos los p-valores son significativos, lo que indica que esta regresión claramente se ajusta a los datos observados. Si se mira con detenimiento la correlación, se ve que el R cuadrado ajustado es de 0.9852. Esto indica que el 98.52% de la variación que se observa en los datos puede ser explicada utilizando esta regresión.
5.4 Representación gráfica de las regresiones con ggplot2
El paquete ggplot2 es uno de los paquetes mejor valorados para realizar figuras en R. El paquete ggplot2 no viene preinstalado en R Commander, por lo que hay que hacerlo manualmente. La instalación del paquete ggplot2 se hace con la siguiente función:
install.packages("ggplot2")
Una vez instalado en nuestro R, lo cargamos en R Commander siguien la ruta Tools - Load package(s)....
5.4.1 Intervalos de confianza y de predicción
Los intervalos de confianza se definen en base a un parámetro en concreto. En el caso de una regresión lineal simple, este parámetro es la recta de mínimos cuadrados que mejor se ajusta a las observaciones.
Los intervalos de confianza siempre llevan asociados un porcentaje, que suele ser del 95%. El espacio que representa el intervalo de confianza del 95% se refiere a ese espacio donde existe un 95% de probabilidades de que se encuentre realmente esa línea de tendencia en la población general.
Los intervalos de confianza se definen por otras dos líneas: una superior y otra inferior. Cada una de ellas se expresan como sendas ecuaciones.
Por su parte, el intervalo de predicción se refiere a ese intervalo en el que se agrupa prácticamente la totalidad de las observaciones sobre el diagrama de dispersión.
Si se desea evaluar en qué intervalo se encuentra la media de esa regresión, se aplica el intervalo de confianza. Ahora bien, si se quiere predecir cuál es el intervalo completo que puede adquirir el valor de Y para una X dada, se debe utilizar el intervalo de predicción. Mientras que el intervalo de confianza va asociado a un parámetro (media, por ejemplo), el intervalo de predicción va asociado a la dispersión de las observaciones.
5.4.2 Función ggplot()
En el paquete ggplot2 existen una variedad de funciones hechas con distinto propósito. La que interesa especialmente es la función ggplot() conectada con otras funciones. La regresión lineal simple aplicada sobre los datos de las medidas de los molares de Neandertales puede verse en la Figura 68. El código que se ha ejecutado es el siguiente:
ggplot(data = Molares, aes(x = BL.mm, y = MD.mm)) +
geom_point() +
geom_smooth(method = "lm",
formula = y ~ x,
level=0.95)
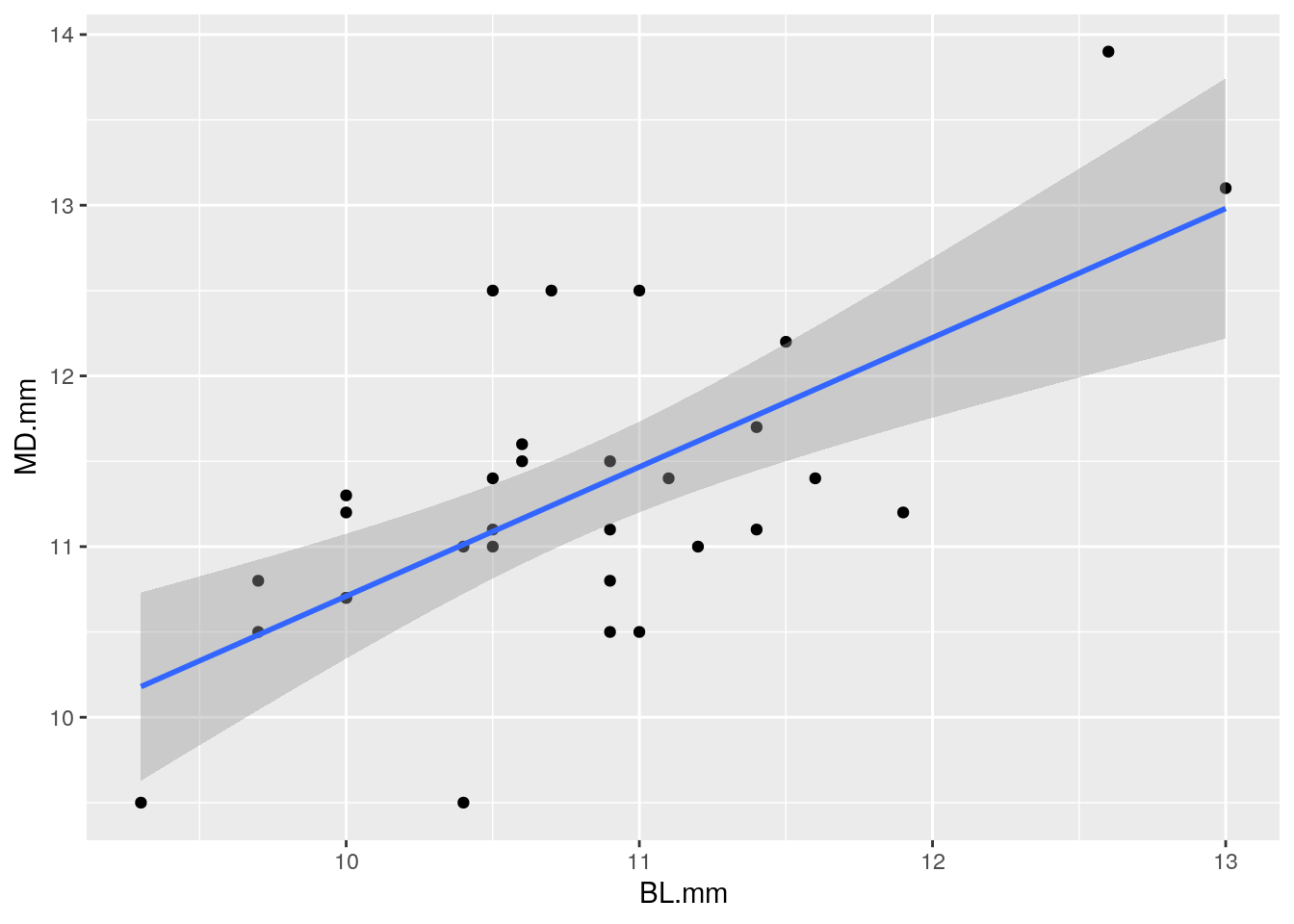
Figura 68: Regresión lineal e intervalo de confianza al 95%. También se representan las observaciones.
En el código ejecutado se han empleado tres funciones encadenadas con el símbolo +, que son ggplot() + geom_point() + geom_smooth().
En el primero de ellos, ggplot() indica el nombre de los datos (Molares) seguido de qué variables van a representarse en el eje X y en el eje Y. El segundo de ellos, geom_point() indica que represente los puntos de cada observación. El tercero, geom_smooth() es el que va a representar la línea de regresión junto con el intervalo que escojamos (confianza o predicción).
En la función geom_smooth() encontramos varios argumentos que son interesantes para mostrar la línea de regresión:
method: se indica indicarlmpara que nos haga un modelo lineal.formula: se indica la fórmula de la regresión. Si son ecuaciones lineales y polinomiales se haría del siguiente modo:y ~ x. Regresión lineal simple.y ~ poly(x,2). Regresión polinomial de segundo grado.y ~ poly(x,3). Regresión polinomial de tercer grado.y ~ poly(x,4). Regresión polinomial de cuarto grado.
level: indica el nivel de significación del intervalo de confianza. Si es un nivel de significación del0.05, se escribelevel = 0.95, lo que representa un intervalo de confianza al 95%.
Es importante destacar que el sombreado que aparece en gris en la Figura 68 hace referencia al intervalo de confianza al 95%, tal y como se mostró en el código previo. Ahora bien, este valor puede modificarse cambiando el argumento level, como se ve en la Figura 69.
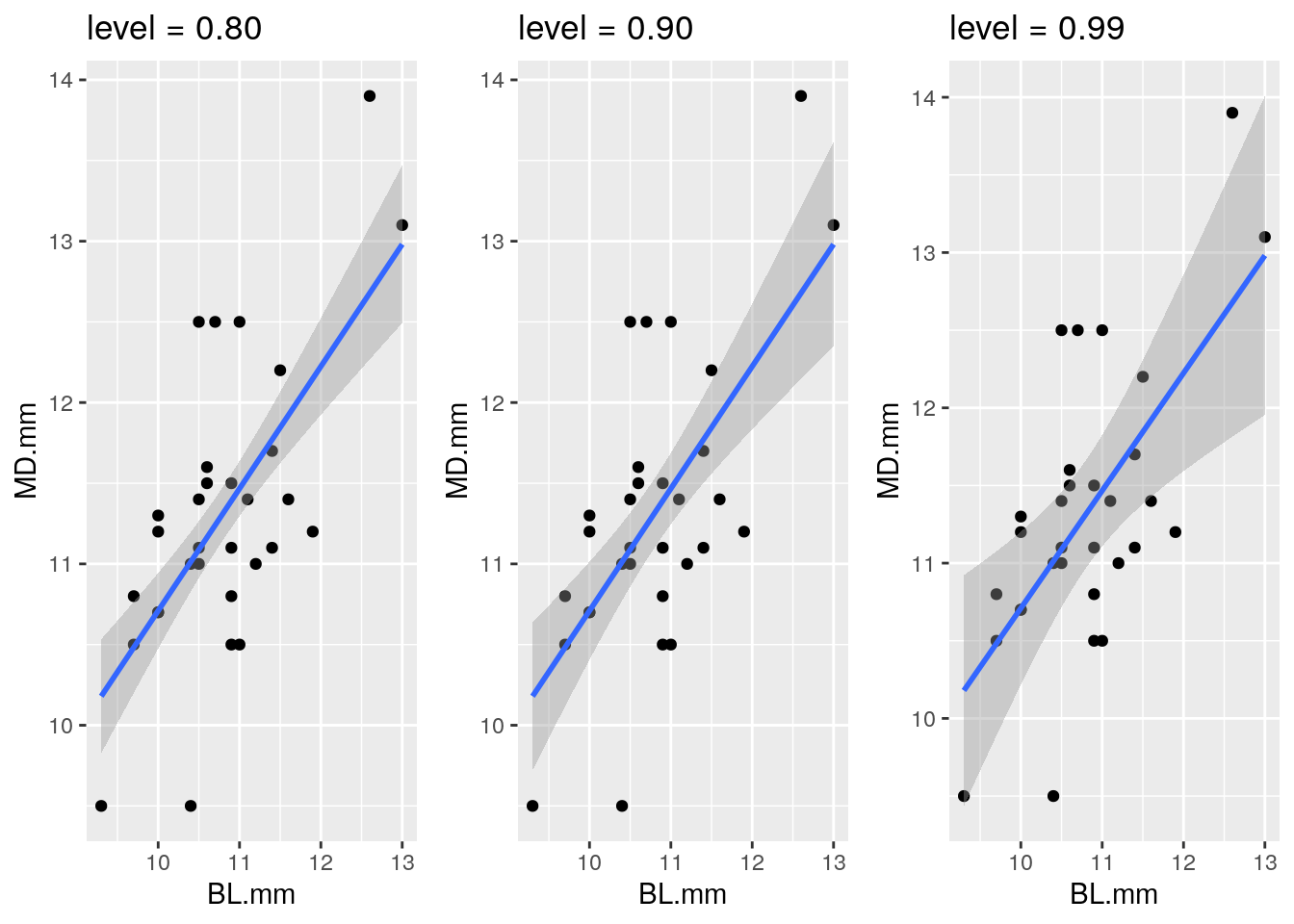
Figura 69: Regresión lineal simple con intervalos de confianza del 80% (izquierda), del 95% (centro) y del 99% (derecha). También se representan las observaciones.
Si se modifica el argumento formula poniendo varios tipos distintos de regresiones polinomiales, se puede observar cómo se va adaptando a los datos según va aumentando el número de grados (Figura 70).
ggarrange(
ggplot(Molares, aes(x = BL.mm, y = MD.mm)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 2), level=0.95) +
ggtitle("y ~ poly(x, 2)"),
ggplot(Molares, aes(x = BL.mm, y = MD.mm)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 3), level=0.95) +
ggtitle("y ~ poly(x, 3)"),
ggplot(Molares, aes(x = BL.mm, y = MD.mm)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 4), level=0.95) +
ggtitle("y ~ poly(x, 4)"),
ncol = 3)
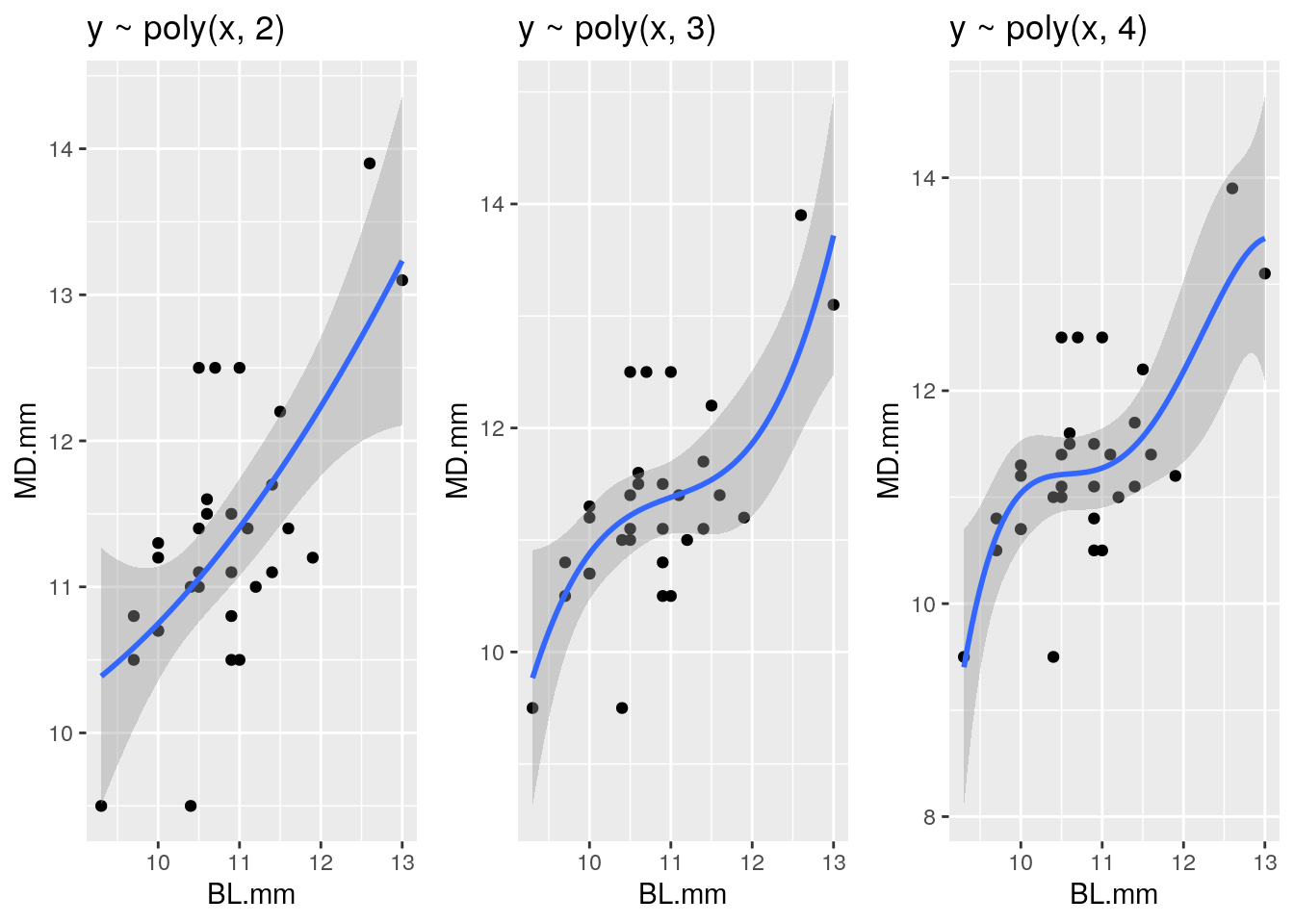
Figura 70: Regresión polinomial de segundo grado (izquierda), tercer grado (centro) y de cuarto grado (derecha). El intervalo de confianza en todas las figuras es del 95%.
Para representar gráficamente el intervalo de predicción (Figura 71) hay que copiar y pegar el siguiente código:
regresion = lm(MD.mm~BL.mm, data=Molares) mpi = cbind(Molares, predict(regresion, interval = "prediction")) ggplot(mpi, aes(x = BL.mm)) + geom_ribbon(aes(ymin = lwr, ymax = upr), fill = "gray", alpha = 0.5) + geom_point(aes(y = MD.mm)) + geom_line(aes(y = fit), colour = "blue", size = 1)
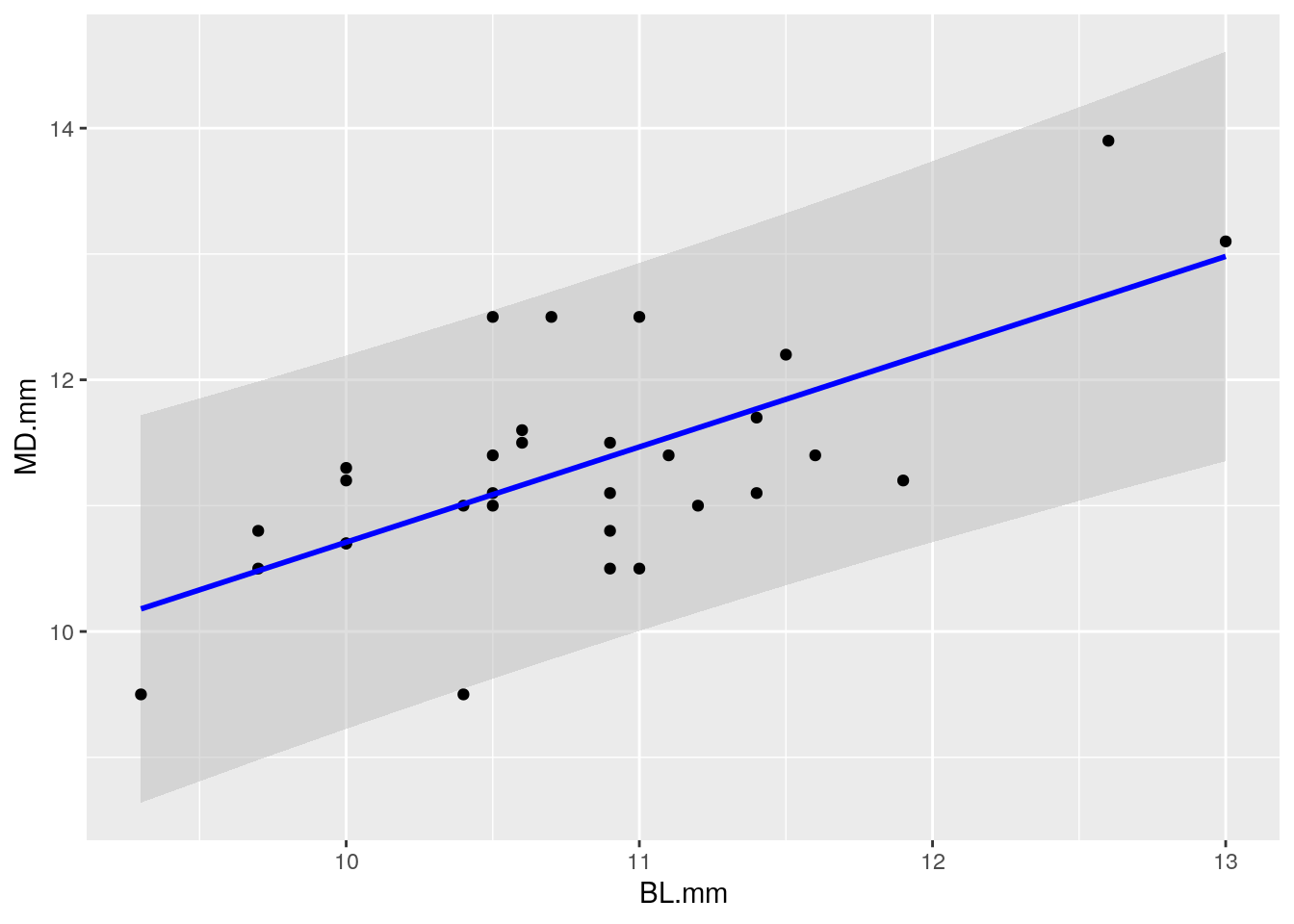
Figura 71: Regresión lineal con el intervalo de predicción.
5.5 Predicción de valores
Una de las funcionalidades de la generación de las ecuaciones de regresión es la de predecir los valores que tendrá la variable dependiente (Y) para un valor dado de la variable independiente (X). Con sustituir simplemente el valor de X en la ecuación se podría obtener su correspondiente valor de Y.
A día de hoy no es posible predecir estos valores usando la interfaz gráfica con menús y submenús de R Commander. Hay que recurrir a la introducción manual de códigos. Por ejemplo, se quiere averiguar cuánto sería el diámetro mesiodistal (MD.mm) cuando el valor del diámetro bucolingual (BL.mm) es 10.25 mm. Además, se quiere mostrar también el intervalo de confianza (con distintos niveles de significación) y el intervalo de predicción.
En la Figura 72 se exponen cuáles son los puntos exactos en el eje Y que se calcularán con los códigos de R.
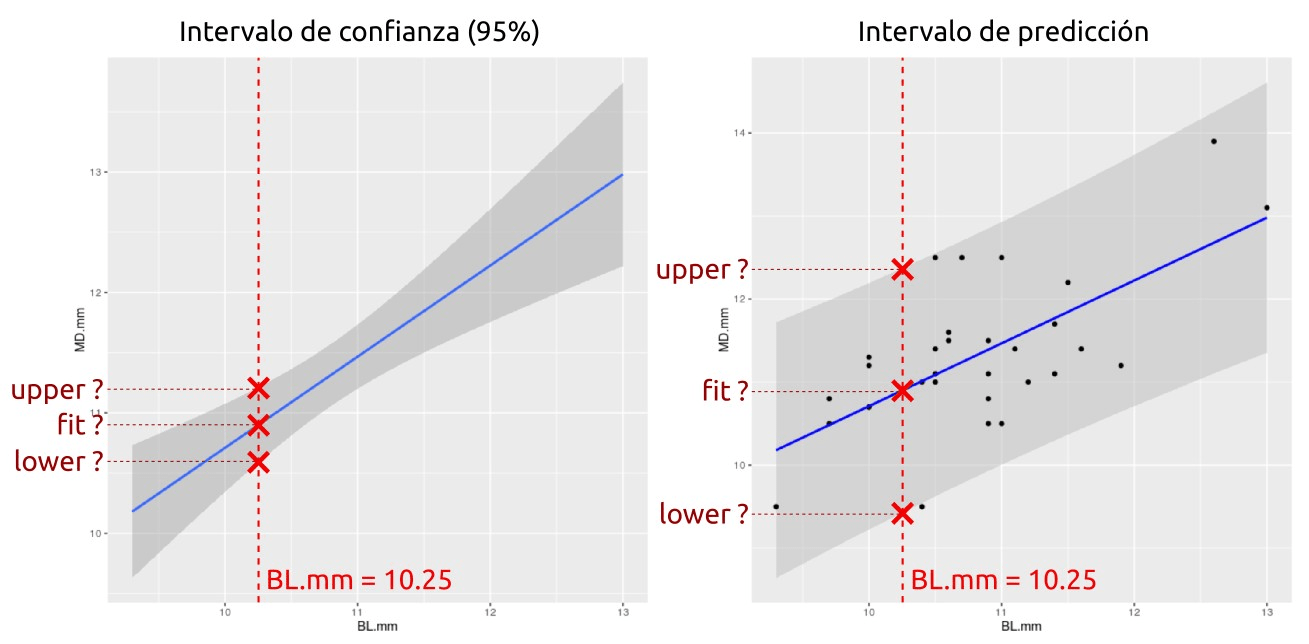
Figura 72: Explicación de los puntos que son predecidos por la ecuación de regresión, tanto para el intervalo de confianza (izquierda) como el intervalo de predicción (derecha).
5.5.1 Intervalos de confianza
Este proceso tiene dos pasos: el primero de ellos es definir el valor de X para el que queremos calcular la Y, y el segundo de ellos es propiamente la función de predicción. Como en el ejemplo se usa un valor de 10.25 mm para la variable X (BL.mm), el código que se debe escribir es el siguiente:
valorX <- data.frame(BL.mm = 10.25)
De este modo, se le asigna a valorX el valor de 10.25 mm. A continuación, se ejecuta la función predict(), en el que se incluye el nombre del modelo de regresión (regresion), el valor que se quiere predecir (valorX), el intervalo que se desea calcular (interval = "confidence") y el nivel de confianza (level = 0.95).
predict(regresion, # Nombre del modelo de regresión
valorX, # Valor a predecir
interval="confidence", # El intervalo escogido
level=0.95) # El nivel de confianza
## fit lwr upr ## 1 10,89893 10,58531 11,21255
El resultado indica que el valor ajustado (fit) es 10.90, el límite de confianza inferior al 95% (lwr) es 10.59 y el superior (upr) es 11.21. Estos valores pueden observarse en la Figura 73.
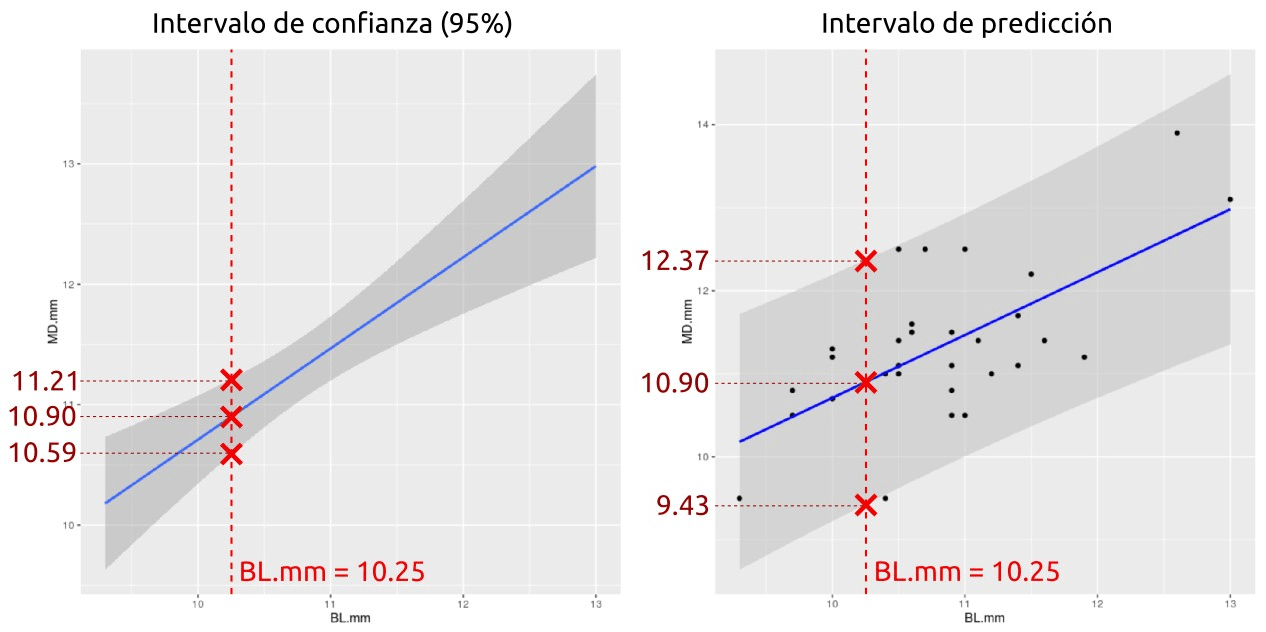
Figura 73: Valores predichos por el modelo para un diámetro bucolingual de 10.25 mm, tanto con el intervalo de confianza (izquierda) como con el intervalo de predicción (derecha).
5.5.2 Intervalos de predicción
Al igual que en el caso del intervalo de predicción visto en la sección anterior, este proceso tiene dos pasos: el primero de ellos es definir el valor de X para el que queremos calcular la Y, y el segundo de ellos es propiamente el comando de predicción. Como en el ejemplo anterior se ha usado un valor de 10.25 mm para la variable X (BL.mm), se va emplear también este valor en el cálculo del intervalo de predicción.
A continuación se ejecuta la función predict() indicando que el intervalo sea el de predicción (interval="prediction").
predict(regresion, valorX, interval="prediction")
## fit lwr upr ## 1 10,89893 9,42737 12,37048
El valor predicho ajustado (fit) es exactamente el mismo que en el caso del cálculo del intervalo de confianza. Esto tiene todo el sentido porque lo que varían son los intervalos, no el modelo como tal. En este caso, los intervalos de predicción inferior (lwr) y superior (upr) son más amplios que sus equivalentes del intervalo de confianza, situándose entre 9.43 y 12.37 mm respectivamente. Estos valores pueden observarse en la Figura 73.
5.6 Interpolar y Extrapolar
Una última consideración, y no por ello menos importante, es la de conocer cuándo se pueden aplicar las regresiones. Con lo de aplicar nos estamos refiriendo a su valor predictivo, tal y como se ha estudiando en la sección anterior. Y para ello es de vital importancia conocer los conceptos de interpolación y extrapolación. Los intervalos de datos que tengamos en el eje X son los responsables de esta diferenciación.
La interpolación es proyectar sobre la regresión el valor de Y para un valor de X que está comprendido entre el mínimo de X y el máximo de X en las observaciones. Por ejemplo, el diámetro bucolingual mínimo y máximo de X (BL.mm) es 9.3 y 13 mm. Para cualquier valor comprendido (o igual) a ambos extremos se está produciendo una interpolación, ya que la regresión está formada en base a esos valores. Ahora bien, una extrapolación se basa en calcular valores de Y para valores de X que están fuera de ese rango de valores reales de X. ¿Cuánto valdría la variable MD.mm (Y) si BL.mm (X) valiera 2 mm ó 15 mm?
Debido a que no se conoce cómo funciona la regresión fuera de los valores con los que fue construida, está totalmente desaconsejado realizar extrapolaciones, ya que se desconoce cómo se comporta el modelo para rangos de valores que no fueron empleados para construir la regresión.
Referencias
Lumley, Marie-Antoinette de, and Giacomo Giacobini. 2013. “Les Néandertaliens de La Caverna Delle Fate (Finale Ligure, Italie). II Les Dents.” L’Anthropologie 117 (3): 305–44. https://doi.org/10.1016/j.anthro.2013.05.002.
Modesto-Mata, Mario, Cecilia García-Campos, Laura Martín-Francés, Marina Martínez de Pinillos, Rebeca García-González, Yuliet Quintino, Antoni Canals, et al. 2017. “New Methodology to Reconstruct in 2-D the Cuspal Enamel of Modern Human Lower Molars.” American Journal of Physical Anthropology 163 (4): 824–34. https://doi.org/10.1002/ajpa.23243.
